Assembling Definition
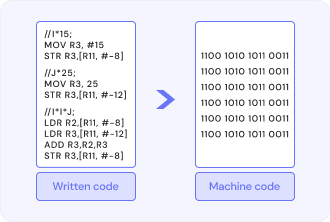
Assembling – one of the most powerful classes of processes in a computer, where a set of human-written instructions is translated into a sequence of bits that the computer processor carries in action one after another without gaps. This is catered for by a computer program, referred to as an assembler.
An assembling is therefore a significant link between the languages of the machines and the high-level programming language which lets a processor in a computer together with a memory to comprehend. Whether you’re working with a top app development company or developing embedded systems in-house, choosing the right assembler determines performance efficiency and compatibility.
The kind of an assembler that the program uses in the assemblage process will depend on the kind of the assemblage. This therefore gives the kind of assembly process depending on the number of reads a program read through the source codes to translate into machine language.
Understanding the assembling process
The assembling process is a very orderly transformation, wherein low-level symbolic instructions are systematically converted into binary machine code, a transformation stemming from human logic into silicon precision. This unlike any other high-level language relying on the compiler or interpreter, assembly language is working right at the metal, which is far away from the hardware.
This close interaction permits no sloppy coding and, therefore, requires absolute precision in translation. Consider that skilled people in low-level operations can be key to bridging the gap between high-level application logic and machine-level execution, especially when performance is critical if you are thinking about how to hire Java developers.
In the first part, the assembler attempts to read the source file line by line; every statement is passed and parsed thoroughly, identifying instructions and assembler directives mapping into hardware-level operations.
Depending on the particular implementation, the assembling can either be a one-pass or two-pass process. A one-pass assembler tries to get down to business right away, resolving labels and generating code simultaneously which speeds things up but can put it in a corner when handling forward references or certain intricate constructs.
The two-pass assembler first scans the whole program to build up a symbol table of labels and addresses; then the second pass fills in all holes by replacing all symbolic references with their real memory addresses while also generating the final machine code.
Hence, this two-stage approach provides an extra layer of the safety net, thereby, making it more reliable when faced with forward-referenced labels without even breaking a sweat. It’s a technique often employed by the top IT companies in the UK to ensure clean execution, accurate memory addressing, and minimal runtime errors in complex systems.
Syntax is checked by the assembler during translation, operand encoding and any necessary memory segmentation. The usual end product would be an object file having executable machine code, relocation information and often metadata for use during debugging or linking at a later stage.
How does assembling translate code into machine instructions

The process of translating assembly code into machine instructions is a no-nonsense, clockwork operation, meticulously guided by the processor’s Instruction Set Architecture (ISA). Here’s how it unfolds step by step:
- Lexical analysis:
The assembler reads the source file and analyzes it down to its bare bones, parsing whatever line it can into meaningful tokens—mnemonics (MOV, ADD), operands (R1, 0x0040), labels and directives. It is a step that really sets up the whole translation process.
- Syntax and semantic analysis:
Each line is verified to ensure that it is in the proper format and contains valid combinations of operands; basically, the compiler checks its grammar, again, the allowed mnemonics and the number and kind of operands must be valid according to the ISA.
- Symbol table construction (First Pass):
Labels and symbols are recorded with associated memory addresses. This step sets the whole flow of the program, which later becomes necessary to resolve any jumps, branches and variable references.
- Address calculation:
To calculate the memory location addresses for each instruction and for data segments, the assembler performs calculations to evaluate the constants, offsets and either relative or absolute addresses needed for branching. Basically, everything must be very evenly planned out with just a slight pip over the address projection of an instruction.
- Opcode generation:
For each mnemonic, the assembler opens the “ISA playbook” to search for its respective binary opcode and then converts it into machine code. This is the conversion of symbolic shorthand into the cold binary, an interface between the abstract and the electrical.
- Operand encoding:
Registers, immediate values and memory addresses are encoded in a manner consistent with the architecture’s binary format. The assembler determines an addressing mode and packs its argument so tightly into one instruction word that there is hardly a wasted bit.
- Label resolution (Second Pass):
The second pass of a two-pass assembler fixes up any remaining references to symbolic labels with actual addresses that were determined in the first pass. Jump and branch offsets are calibrated to be correct to the last clock cycle in control flow.
- Output generation:
The assembler finally releases the object file or executable in binary format into the permeating realms of ELF or PE. It may also come with symbol tables, debugging information and relocation entries in a perfect combination for linking and loading.
- Error reporting:
Through the process, the assembler stays alert for undefined symbols, invalid syntax, or memory overflows. Errors are reported with line numbers and descriptions, pinpointing the trouble spots to aid in debugging.